Artificial
Intelligence Notes
Unit-4
Lecture-1
Expert Systems
The credibility of AI rose to new
heights in the minds of individuals and critics when many Expert Systems (ES)
were successfully planned, developed and implemented in many challenging areas.
As of today, quite a heavy investment is done in this area. The success of
these programs in very selected areas involving high technical expertise has
left people to explore new avenues.
“Expert Systems (ES) are knowledge
intensive programs that solve problems in a domain that requires considerable
amount of technical expertise”.
“An Expert System is a set of programs
that manipulates embedded knowledge to solve problems in a specialized domain
that normally requires human expertise”.
Characteristics of an Expert System:
·
They
should solve difficult programs in a domain as good as or better than human
experts.
·
They
should possess vast quantities of domain-specific knowledge to the minute
details.
·
These
systems permit the use of heuristic search process.
·
They
explain why they ask a question and justify their conclusions.
·
They
deal with uncertain and irrelevant data.
·
They
communicate with the users in their own natural language.
·
They
possess the capacity to cater the individual’s desire.
·
They
provide extensive facilities for ‘symbolic processing’ rather than ‘numeric
processing’.
·
A
final characteristic is from the point of economists and financial people: They
should mint money. Expert Systems need heavy investment and there should be
considerable ‘Return on Investment’ (ROI).
Architecture and Modules of Expert
System
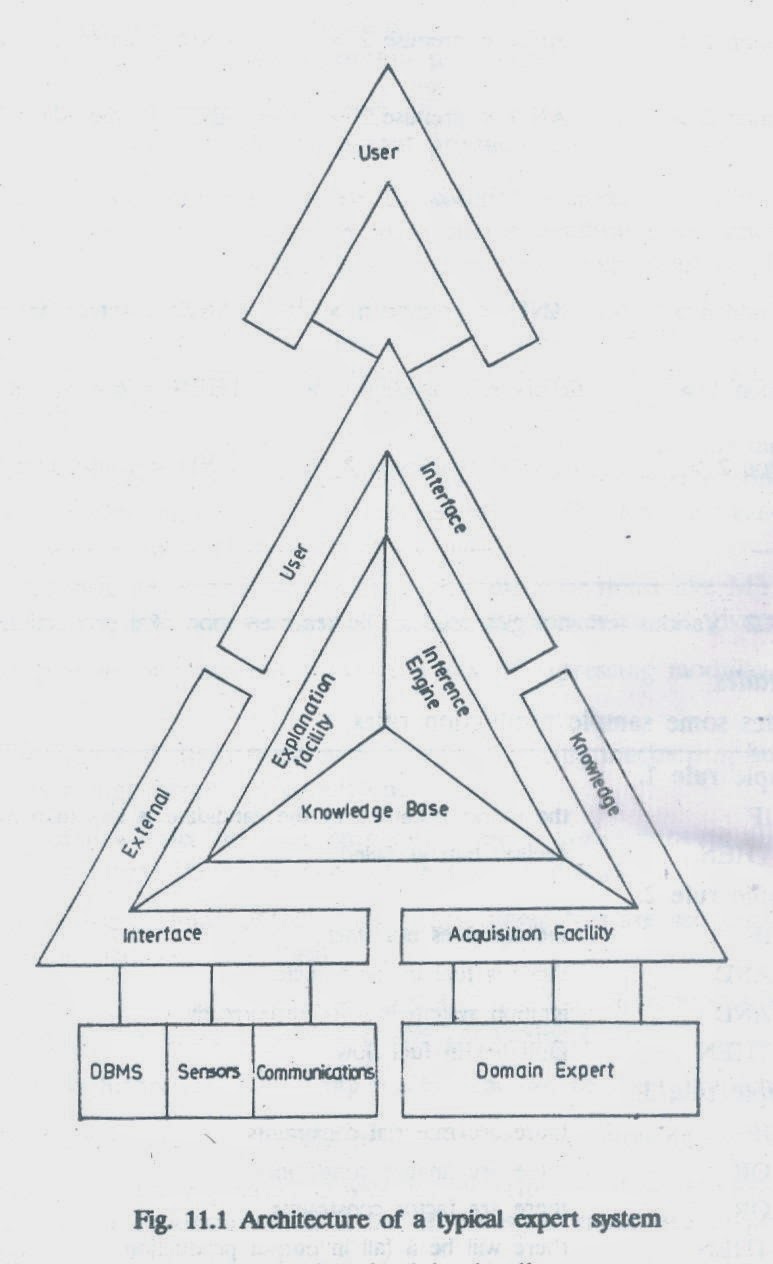
The fundamental modules of an expert
system are:-
·
Knowledge
Base
·
User
Interface
·
Inference
Engine
·
Explanation
Facility
·
Knowledge
Acquisition Facility
·
External
Interface
1. Knowledge
Base: The core module of any expert system is its Knowledge-Base (KB).
It is a warehouse of the domain-specific knowledge captured from the human
expert via the knowledge acquisition module.
There are many ways of representing the knowledge in the knowledge-base
such as logic, semantic nets, frames, scripts, production rules etc.
2. User Interface: User Interface provides the needed
facilities for the user to communicate with the system. A user normally would
like to have a construction with the system for the following aspects:
·
To
get remedies for his problem.
·
To
know the private knowledge (heuristics) of the system.
·
To
get some explanations for specific queries.
Presenting a
real-world problem to the system for a solution is what is meant in having a
consultation. Here, the user-interface provides as much facilities as possible
such as menus, graphical interface etc. to make the dialogue user-friendly and
lively.
3. Inference
Engine: Also called as ‘rule interpreter’ an inference engine (IE),
performs the task of matching antecendents from the responses given by the user
and firing rules.
Basically there are two
approaches:-
Forward Chaining- This works by matching the existing conditions of the problem (given
facts) with the antecendents of the rule in the knowledge base. Forward
chaining is also known as data driven search or antecendent search.
Backward Chaining- This is a reverse process of forward chaining. Here the rule
interpreter tries to match the ‘THEN condition’ instead of the ‘IF condition’.
Because of this backward chaining is also called consequent driven or goal
driven search.
4. Explanation
Facility: Getting answers to specific queries forms the explanation
mechanism of the expert system. Basically any user would like to ask the
following basic questions ‘why’ & ‘how’.
Conventional
programs do not provide these facilities. Explanation facility helps the user
in the following ways:-
·
If
the user is a domain expert, it helps in identifying what additional knowledge
is needed.
·
Enhances
the user’s confidence in the system.
·
Serves
as a tutor in sharing the System’s knowledge with the user.
·
Explanation
Facility is a part of the user interface that carries out the above tasks.
5. Knowledge
Acquisition Facility: The major bottleneck in Expert System development
is knowledge acquisition. Knowledge Acquisition facility creates a congenial
atmosphere for the expert to share the expertise with the system. KAF creates a
congenial atmosphere for the expert to share the expertise with the system.
6. External Interface: This provides the communication
between the Expert System and the
external environment. When there is a formal consultation, it is done via the
user interface. In real time expert systems when they form a part of the closed
loop system, it is not proper to expect human intervention every time to feed
in the conditions prevailing & get remedies. Moreover, the time gap is too
narrow in real time system. The external interface with its sensors gets the
minute by minute information about the situation & act accordingly.
Knowledge Acquisition Strategies:
1. Protocol Analysis: In this method, the expert is asked
to think aloud and try to express the mental process while solving the problem.
The protocol, consisting of the knowledge engineer’s observation & expert’s
thought process is analyzed at a later stage for specific features of the type
of problem. In this method, the knowledge engineer does not interrupt while the
expert is on the work.
2. Interviews & Introspection:
This is another method and most commonly used. In this method, the knowledge
engineer familiarizes the concepts about the domain and poses questions or
problems to the experts who in turn, provide answers or solutions that help in
revealing some heuristic knowledge.
3. Observation
at site: In this method, the elicitor acts as a passive element and
watches the expert in actual action. Procedural knowledge is obtained by this
method.
4. Discussion about the problem: In this category there are three
methods:-
a) Problem Description- In problem description, the expert is asked to
give sample problems, for each category of answer. This method will help in
identifying the foundational characteristics of the problems.
b) Problem Discussion- Problem discussion method involves discussion
about a problem to the domain expert. The needed data, knowledge and procedures
evolve by this method. Knowledge of finer granularity emerges from the discussion.
c) Problem Analysis: The problem analysis part is similar to protocol
analysis, wherein the expert is presented with a series of problems and asked
to think and find solutions for the same.
5.
Discussion about the system: This method involves the prototype system that has
been developed. Three major methods are:-
a) Tuning the System: In tuning the system, the domain specific expert
is asked to provide a set of classic problems and solutions are obtained from
the system. The solutions are then compared with the solutions obtained by the
human expert and the system is tuned by adding knowledge of high granularity.
b) Verifying the system: In verifying the system, the expert is
totally explained about the intricacies of the system and is asked to verify
the working of the system. This is a tedious task.
c) Validating the system: In validating the system, the results of the
system and that of the expert are given to the outside experts to find out the
validity of the solution.
Difficulties in Knowledge Acquisition
·
Domain
experts store their private knowledge subconsciously. They do not keep a
written record of their heuristics. So, unless and until a problem comes that
needs that private piece of knowledge, it remains passive and hidden.
·
Domain
experts have the problem of effective communication. Most experts find it
difficult to explain their reasoning process. Lack of proper communications
makes knowledge acquisition process very tedious and inefficient.
·
Much
of the human expertise is basically intuitive which is the capability of
skilled pattern recognition. Intuition is very hard to verbalize.
Artificial
Intelligence Notes
Unit-4
Lecture-2
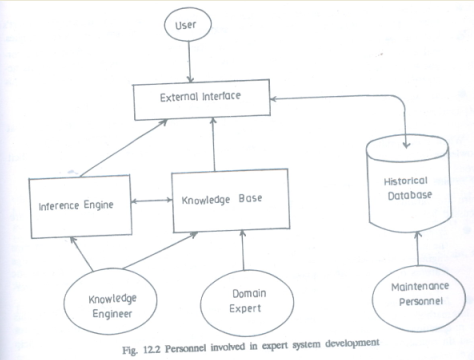
Personnel Involved in Expert System Development
The following four classes of
personnel are involved:
·
User: A very passive element in the
development process. Specifies the overall problem for which expert system is
needed. Plays a small role in problem identification and comes into picture
when the system is fully developed and implemented.
·
Knowledge Engineer: An active player in the development
team. Associated with others right from the identification phase until the
implementation of the full system. Involved in the development of the inference
engine, structure of knowledge base and user interface if a programming
language is chosen. Helps in choosing a tool for development by explaining the
features of it to the expert.
·
Domain expert: Another active player in the
development process. Transfers the entire knowledge about the domain to the
system. Also identifies and plugs loop-holes in the system. Totally committed
for the development of the system right from the beginning.
·
System maintenance personnel: They are also passive in nature and
are involved in maintenance of the system and the historical database
The following fig. shows the roles
played by various personnel:
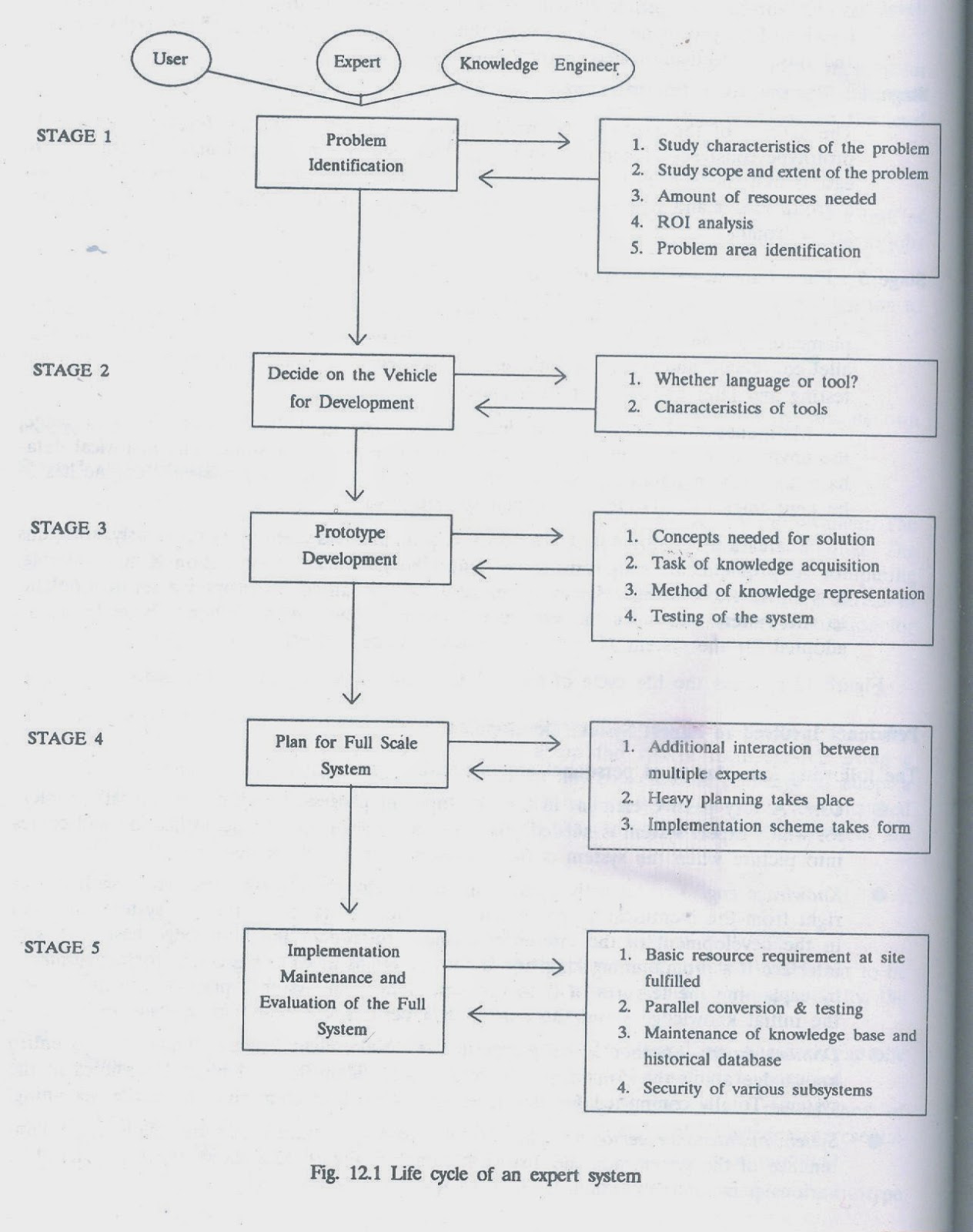
Expert System Life Cycle
Stage 1: Identification of the problem
Stage 2: Decision about the mode of
development
Stage 3: Development of a prototype
Stage 4: Planning for a full-scale system
Stage 5: Final Implementation, Maintenance
& Evaluation
Identification of the problem:- In this stage, the expert and the
knowledge engineer interact to identify the problem. The major points are
discussed before for the characteristics of the problem are studied. The scope
and extent are pondered. The amount of resources needed e.g. men, computing
resources, finance etc. are identified. The return-of-investment (ROI) analysis
is done. Areas in the problem which can give much trouble are identified and a
conceptual solution for that problem and the overall specification is made.
Decision about the mode of development:- Once the problem is identified,
the immediate step would be to decide on the vehicle for development. The
knowledge engineer can develop the system from scratch using a programming like
PROLOG or LISP or any conventional language or adopt a shell for development.
In this stage, various shells and tools
are identified and analyzed for suitability. Those tools whose features fit the
characteristics of the problem are analyzed in detail.
Development of a Prototype:-
Before developing a prototype, the
following are the prerequisite activities:-
·
Decide
on what concepts are needed to produce the solution. One important factor to be
decided here is the level of knowledge (granularity). Starting with course
granularity, the system proceeds towards fine granularity.
·
After
this, the task of knowledge acquisition begins. The knowledge engineer and the
domain expert interact frequently and the domain-specific knowledge is
extracted.
·
Once
the knowledge is acquired, the knowledge engineer decides on the method of
representation. In identification phase, a conceptual picture of knowledge
representation would have emerged. In this stage, that view is either enforced
or modified.
·
When
the knowledge representation scheme and the knowledge is available, a prototype
is constructed. This prototype undergoes the process of testing for various
problems and revision of the prototype takes place.
Planning for a full scale system:-
The success of the prototype provides
the needs impetus for the full scale system. In prototype construction, the
area in the problem which can be implemented with relative ease is first
chosen. In the full-scale implementation, sub-system development is assigned a
group leader and schedules are drawn. Use of Gantt chart, PERT or CPM
techniques are welcome.
Final Implementation, Maintenance & Evaluation:-
This is the final life cycle stage of
an expert system. The full scale system developed is implemented at this site.
The final system undergoes rigorous testing and later handled over to the user.
Maintenance of the system implies
tuning of the knowledge base because knowledge, the environment and types of
problems that arrive are never static. The historical database has to be
maintained and the minor modifications made on inference engine has to be kept
track off. Maintenance engulfs security also.
Evaluation is a difficult task for
any AI program. As mentioned previously, solutions for AI problems are only
satisfactory. Since the yardstick for evaluation is not available, it is difficult
to evaluate. However, utmost what one can do is to supply a set of problems to
the system and a human expert and compare the results.
Limitations of present day Expert
Systems:
·
Present
day ES focus on very specific topics only like computer faults, radiology,
diagnostic skills etc. The major reason being the difficulty in extracting
knowledge, building and maintaining large knowledge bases.
·
We
have seen that knowledge can be represented by a few methods only. These are
totally insufficient. Lack of proper knowledge representation mechanisms hamper
progress in expert system development.
·
The
construction process of an expert system is a laborious one. Lot of resources
are needed today.
·
Present
day expert system do not have any common sense knowledge. This is a major
drawback for the success of the system.
·
Though
some of the systems have the facility of knowledge acquisition by directly
interacting with the experts, for majority of the systems, there is a dire need
for a knowledge engineer.
·
There
is no flexibility for the user to state the problem. Users are to describe the
problem in a strictly defined formal language which every user might not be
able to. Because of this reason, expert systems have not been able to cater to
a wide spectrum activities of people.
Major Application Areas of Expert Systems:-
Ø Analysis
Ø Control
Ø Designing
Ø Diagnosis
Ø Monitoring
Ø Planning
Ø Prediction
Ø Repair
Examples of Expert Systems
·
DENDRAL
does the inferring process of structure elucidation of chemical compounds.
·
MYCIN,
an expert system for diagnosis of bacterial infections and effectively handles
uncertain data.
·
XCON/R1,
a system in use at Digital Equipment Corporation for configuring VAX computers.
Artificial
Intelligence Notes
Unit-4
Lecture-3
LISP- An AI Language
LISP (LISt Processing) is an AI
programming language developed by John McCarthy in late 1950’s. LISP is a
symbolic processing language that represents information in lists and
manipulates these lists to derive new information.
Preliminaries of LISP
LISP language is exclusively used for
manipulating lists. The major characteristic is that the basic elements are
treated as symbols irrespective of whether they are numeric or alphanumeric.
The basic data element of LISP is an
atom, a single word or number that stands for some object or value. Being the
basic data element in LISP, an atom is indivisible. LISP has two basic types of
atoms, numbers and symbols.
A collection of numbers or symbols
constitute a list. It is a convention that all the members of the list have
something in common. Some examples of a list are:-
(APPLE ORANGE GRAPES MANGO)
(MILLIMETRE CENTIMETRE DECIMETRE
METRE)
(BULLOCK-CART CYCLE MOPED SCOOTER
CAR)
(78 65 71 70 68)
Note that the entire list is enclosed
within a set of parenthesis. All the lists have something in common. In the
list given above, first group is a list of fruits, second is for unit of
measurement, third, mode of transportation and fourth, marks scored by a set of
students. Each member of the list, called an element of the list, is a symbol
separated by blank space between them. It is also possible to have sub-lists
with a list. Consider the list for mode of transportation. It can have a sub
list as:
(BULLOCK-CART (HERCULES ATLAS HERO)(TVS50
KELVINATOR MOFA)(LML-VESPA
BAJAJ NARMADA)(MARUTI AMBASSADOR
FIAT)
Such a combination of lists within
lists are called “nested” or “multiple” or “complex” list. The number of
parentheses, opening and closing must be same. If not, the system will flash an
error message.
One important type of list is the
empty list. An empty list does not have any member or element in it. It is
represented as ( ). LISP understands an empty list as NIL. Inside the computer,
a list is represented as a chain of CONS cells. A CONS cell is a simple data
structure with two addresses. One address indicates the element of the list and
the second address the succeeding element of the list. A chain of CONS cell
constitutes a list.
The following fig. shows how simple
and nested cells are represented in the CONS cell format.

LISP FUNCTIONS
A LISP program is a collection of
small routines which define simple functions. In order that complex functions
may be written, the language comes with a set of basic functions called
primitives. These primitives serve commonly required operations.
Apart from these primitives, LISP
permits you to define your own functions. Because of this independence, LISP is
highly flexible.
In data structures, you might have
encountered infix, prefix and postfix representations. LISP uses prefix
notations for its operations.
The basic primitives of LISP are classified as:-
« Arithmetic primitives
« Boolean primitives
« List manipulation primitives
Arithmetic Primitives: The arithmetic primitives correspond to basic
arithmetic operations of addition, subtraction, multiplication and division.
Since LISP uses prefix representation, all arithmetic operations are carried
out on data represented in prefix form. To add two numbers, say 20 and 20, the
prefix notation is +20 20.
In this fashion only LISP arithmetic
primitives exist except that they have been enclosed in parentheses. Hence
addition in LISP is carried out as (+20 20) for which the system responds by 40.
Different dialects use different syntax. For addition, some dialects adopt a +
sign while others a PLUS.
So if one has to perform the
following addition:
25+35+45+55+65+75
The command is
(+25(+35(+45(+55(+65 75)))))
Other arithmetic primitives are
1.
DIFFERENCE
or –sign.
2.
TIMES
or *sign.
3.
QUOTIENT
or /sign.
Boolean Primitives: These primitives provide a result
which is Boolean in nature i.e. True or False.
Some of them require only one
argument while others need more than one.
Some such primitives are:-
1.
Atom:- The purpose is to find out whether
the element is an atom or not.
e.g.
(ATOM RAMAN)
T
(ATOM 26 35 42 86))
NIL
2.
NUMBERP:- Determines if the atom is a number
or not.
e.g.
(NUMBERP 20)
T
(NUMBERP RAMAN)
NIL
3.
LISTP:- Determines if the input is a list
or not.
e.g. (LISTP
(25 35
46 75))
T
(LISPT RAMAN)
NIL
4.
ZEROP:-
To find out whether the number is zero or not.
e.g.
(ZEROP 26)
NIL
(ZEROP 0)
T
5.
ODDP:-
To find out whether the given input number is odd.
e.g. (ODDP
65)
T
(ODDP 60)
NIL
6.
EVENP:-
To find out whether the input is even or not.
e.g. (EVENP
78)
T
(EVENP 9)
NIL
7.
EQUAL:-
To find out whether two given lists are equal.
e.g. (EQUAL ‘(JANKIRAMAN SARUKESI)
‘(JANKIRAMAN SARUKESI))
T
(EQUAL
‘(75 67 94)
‘(43 65 987))
8.
GREATER:-
To find out whether the first is greater than second.
e.g. (GREATERP
’46 ’86)
NIL
(GREATERP ’35 ’20)
9.
LESSERP:-
To find out whether the first is lesser than the second.
e.g. (LESSERP
’65 ’90)
T
(LESSERP ’89 ’31)
NIL
List manipulation
Primitives
The purpose of list manipulation primitives are for
1. Creating a new list.
2. Modifying an existing list with addition, deletion
or replacement of an atom.
3. Extracting portions of a list.
In LISP, values are assigned to variables by SETQ
primitive. The primitive has two arguments the first being the variable and
second the value to be assigned to the variable. The value can be an atom or a
list itself.
e.g.
(SETQ A 22) when evaluated assigns 22 to variable
A.
(SETQ TV ‘ONIDA) would assign TV=ONIDA when
evaluated.
LIST Definition:
A LIST is defined using a single quote. Sometimes, the
LIST function may also be used.
e.g. To define a list of fruits we can adopt any of
the methods
(SETQ
FRUITS ‘(APPLE ORANGE
GRAPES))
Or
(LIST
‘APPLE ‘ORANGE ‘GRAPES)
LIST Construction:
LISTS are constructed using CONS primitive. CONS
primitive adds a new element to the front of the existing list. This primitive
needs two arguments and returns a single list.
The following example will explain the purpose.
e.g.
1. (CONS ‘P
’(Q R
S))
(P Q
R S)
2. (CONS ‘RAM
‘(LAKSHMAN BHARAT SHATRUGHNAN)
(RAM LAKSHMAN
BHARAT SHATRUGHNAN)
While the CONS primitive adds a new list to the front
of the existing list, the primitive APPEND adds it to the tail of the existing
list. Here also, the lists are identified by single quotes.
e.g.
1. (APPEND
‘RAM ‘(LAKSHMAN BHARAT SHATRUGHNAN)
(LAKSHMAN BHARAT SHATRUGHNAN
RAM)
Extracting Portions of a LIST:-
Extracting portions of a list pertains to decomposing
the list and getting an atom out of it. For this purpose, LISP provides two
major primitives. They are CAR and CDR.
The CAR primitive returns the first element of the
list.
e.g.
1. (CAR ‘(RAM
LAKSHMAN BHARAT
SHATRUGHNAN)
RAM
2. (CAR ‘((32
36) (56 54)
(67 31))
(32 36)
The CDR primitive returns the list excluding the first
element.
e.g.
1. (CDR
‘(RAM LAKSHMAN BHARAT
SHATRUGHNAN)
LAKSHMAN BHARAT SHATRUGHNAN
2. (CDR
‘((32 36) (56
54) (67 31))
(56 54)
(67 31)
Using these two list manipulating primitives it is
possible to extract any portion of the list. For e.g. if we would like to get
the element BHARAT from the list given as follows:-
(RAM
LAKSHMAN BHARAT SHATRUGHNAN)
We will adopt the following method:-
Step1: Break the list into two using CDR
function
(CDR
‘(RAM LAKSHMAN BHARAT
SHATRUGHNAN)
(LAKSHMAN
BHARAT SHATRUGHNAN)
Step2: Apply CDR again to remove LAKSHMAN
out of the list.
(CDR
‘(LAKSHMAN BHARAT SHATRUGHNAN))
(BHARAT
SHATRUGHNAN)
Step 3: Apply CAR function on the list to
get the element BHARAT
(CAR
‘(BHARAT SHATRUGHNAN))
(BHARAT)
The entire
operation can be written as a single LISP statement as:-
(CAR (CDR (CDR
‘(RAM LAKSHMAN BHARAT
SHATRUGHNAN))))
One important point to note is that CAR and CDR
primitives operate on lists only. When you try to operate them on individual
atoms, the system will flash an error message.
Apart from these primitives, there
exist other functions for operations on LISP. Some of them are:-
1. LENGTH:
A LISP function to find the length of the list.
2. REVERSE:
A function to reverse the given length.
3. LAST: To
return the last element of the list.
4. LOCATE:
To identify where a particular element exists in the list.
5. REPLACE:
Replace a particular element in the list.
covers great syllabus of Artificial Intelligence Online Course
ReplyDelete