DEADLOCK:
A deadlock is a situation when a process in the system has
acquired some resources and waiting for more resources which are acquired by
some other process which in turn is waiting for the resources acquired by this
process. Hence, none of them can proceed and OS cant do any work.
In order for deadlock to occur, four
conditions must be true.
- Mutual exclusion - Each resource is either currently allocated to exactly one process or it is available. (Two processes cannot simultaneously control the same resource or be in their critical section).
- Hold and Wait - processes currently holding resources can request new resources
- No preemption - Once a process holds a resource, it cannot be taken away by another process or the kernel.
- Circular wait - Each process is waiting to obtain a resource which is held by another process.
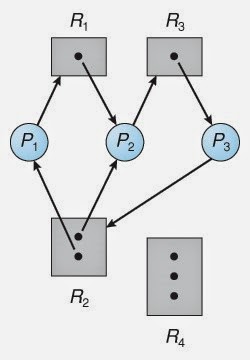
Resource allocation graph with a deadlock
Methods
for Handling Deadlocks
- Generally speaking there are three ways of handling deadlocks:
- Deadlock prevention or avoidance - Do not allow the system to get into a deadlocked state.
- Deadlock detection and recovery - Abort a process or preempt some resources when deadlocks are detected.
- Ignore the problem all together - If deadlocks only occur once a year or so, it may be better to simply let them happen and reboot as necessary than to incur the constant overhead and system performance penalties associated with deadlock prevention or detection. This is the approach that both Windows and UNIX take.
- In order to avoid deadlocks, the system must have additional information about all processes. In particular, the system must know what resources a process will or may request in the future. ( Ranging from a simple worst-case maximum to a complete resource request and release plan for each process, depending on the particular algorithm. )
- Deadlock detection is fairly straightforward, but deadlock recovery requires either aborting processes or preempting resources, neither of which is an attractive alternative.
- If deadlocks are neither prevented nor detected, then when a deadlock occurs the system will gradually slow down, as more and more processes become stuck waiting for resources currently held by the deadlock and by other waiting processes. Unfortunately this slowdown can be indistinguishable from a general system slowdown when a real-time process has heavy computing needs.
Deadlock
Prevention
- Deadlocks can be prevented by preventing at least one of the four required conditions:
-Mutual
Exclusion
·
Shared resources such as read-only
files do not lead to deadlocks.
·
Unfortunately some resources, such
as printers and tape drives, require exclusive access by a single process.
-Hold
and Wait
·
To prevent this condition processes
must be prevented from holding one or more resources while simultaneously
waiting for one or more others. There are several possibilities for this:
o
Require that all processes request
all resources at one time. This can be wasteful of system resources if a
process needs one resource early in its execution and doesn't need some other
resource until much later.
o
Require that processes holding
resources must release them before requesting new resources, and then
re-acquire the released resources along with the new ones in a single new
request. This can be a problem if a process has partially completed an
operation using a resource and then fails to get it re-allocated after releasing
it.
o
Either of the methods described
above can lead to starvation if a process requires one or more popular
resources.
-No
Preemption
·
Preemption of process resource
allocations can prevent this condition of deadlocks, when it is possible.
o
One approach is that if a process is
forced to wait when requesting a new resource, then all other resources
previously held by this process are implicitly released,
( preempted ), forcing this process to re-acquire the old resources
along with the new resources in a single request, similar to the previous
discussion.
o
Another approach is that when a
resource is requested and not available, then the system looks to see what
other processes currently have those resources and are themselves
blocked waiting for some other resource. If such a process is found, then some
of their resources may get preempted and added to the list of resources for
which the process is waiting.
o
Either of these approaches may be
applicable for resources whose states are easily saved and restored, such as
registers and memory, but are generally not applicable to other devices such as
printers and tape drives.
-Circular
Wait
·
One way to avoid circular wait is to
number all resources, and to require that processes request resources only in
strictly increasing ( or decreasing ) order.
·
In other words, in order to request
resource Rj, a process must first release all Ri such that i >= j.
·
One big challenge in this scheme is
determining the relative ordering of the different resources
Avoidance
Deadlock can be avoided if certain
information about processes are available to the operating system before
allocation of resources, such as which resources a process will consume in its
lifetime. For every resource request, the system sees whether granting the
request will mean that the system will enter an unsafe state, meaning a
state that could result in deadlock. The system then only grants requests that
will lead to safe states.[1]
In order for the system to be able to determine whether the next state will be
safe or unsafe, it must know in advance at any time:
- resources currently available
- resources currently allocated to each process
- resources that will be required and released by these processes in the future
It is possible for a process to be
in an unsafe state but for this not to result in a deadlock. The notion of
safe/unsafe states only refers to the ability of the system to enter a
deadlock state or not. For example, if a process requests A which would result
in an unsafe state, but releases B which would prevent circular wait, then the
state is unsafe but the system is not in deadlock.
One known algorithm that is used for
deadlock avoidance is the Banker's algorithm, which requires resource usage limit to be known in
advance.[1]
However, for many systems it is impossible to know in advance what every
process will request. This means that deadlock avoidance is often impossible.
Two other algorithms are Wait/Die
and Wound/Wait, each of which uses a symmetry-breaking technique. In both these
algorithms there exists an older process (O) and a younger process (Y). Process
age can be determined by a timestamp at process creation time. Smaller
timestamps are older processes, while larger timestamps represent youngeA
Under deadlock detection, deadlocks
are allowed to occur. Then the state of the system is examined to detect that a
deadlock has occurred and subsequently it is corrected. An algorithm is
employed that tracks resource allocation and process states, it rolls back and
restarts one or more of the processes in order to remove the detected deadlock.
Detecting a deadlock that has already occurred is easily possible since the
resources that each process has locked and/or currently requested are known to
the resource scheduler of the operating system.[9]
Deadlock detection techniques
include, but are not limited to, model checking.
This approach constructs a finite state-model on which it performs a progress analysis and finds
all possible terminal sets in the model. These then each represent a deadlock.
After a deadlock is detected, it can
be corrected by using one of the following methods:
- Process Termination: One or more process involved in the deadlock may be aborted. We can choose to abort all processes involved in the deadlock. This ensures that deadlock is resolved with certainty and speed. But the expense is high as partial computations will be lost. Or, we can choose to abort one process at a time until the deadlock is resolved. This approach has high overheads because after each abort an algorithm must determine whether the system is still in deadlock. Several factors must be considered while choosing a candidate for termination, such as priority and age of the process.
- Resource Preemption: Resources allocated to various processes may be successively preempted and allocated to other processes until the deadlock is broken.
Recovery
From Deadlock
- There are three basic approaches to recovery from deadlock:
- Inform the system operator, and allow him/her to take manual intervention.
- Terminate one or more processes involved in the deadlock
- Preempt resources.
-
Process Termination
·
Two basic approaches, both of which
recover resources allocated to terminated processes:
o
Terminate all processes involved in
the deadlock. This definitely solves the deadlock, but at the expense of
terminating more processes than would be absolutely necessary.
o
Terminate processes one by one until
the deadlock is broken. This is more conservative, but requires doing deadlock
detection after each step.
·
In the latter case there are many
factors that can go into deciding which processes to terminate next:
1.
Process priorities.
2.
How long the process has been
running, and how close it is to finishing.
3.
How many and what type of resources
is the process holding. ( Are they easy to preempt and restore? )
4.
How many more resources does the
process need to complete.
5.
How many processes will need to be
terminated
6.
Whether the process is interactive
or batch.
7.
( Whether or not the process has
made non-restorable changes to any resource. )
-
Resource Preemption
·
When preempting resources to relieve
deadlock, there are three important issues to be addressed:
1.
Selecting
a victim - Deciding which resources to
preempt from which processes involves many of the same decision criteria
outlined above.
2.
Rollback - Ideally one would like to roll back a preempted process
to a safe state prior to the point at which that resource was originally
allocated to the process. Unfortunately it can be difficult or impossible to
determine what such a safe state is, and so the only safe rollback is to roll
back all the way back to the beginning. ( I.e. abort the process and make it
start over. )
3.
Starvation
- How do you guarantee that a
process won't starve because its resources are constantly being preempted? One
option would be to use a priority system, and increase the priority of a
process every time its resources get preempted. Eventually it should get a high
enough priority that it won't get preempted any more.
Device Management Functions:
•
Track status of each device (such as tape drives, disk
drives, printers, plotters, and terminals).
•
Use preset policies to determine which process will get
a device and for how long.
•
Allocate the devices.
•
Deallocate the devices at 2 levels:
–
At process level when I/O command has been executed
& device is temporarily released
–
At job level
when job is finished & device is permanently released.
Dedicated Devices
•
Assigned to only one job at a time and serve that job
for entire time it’s active.
•
E.g., tape drives, printers, and plotters, demand this
kind of allocation scheme, because it would be awkward to share.
•
Disadvantage -- must be allocated to a single user for
duration of a job’s execution.
•
Can be quite inefficient, especially when device isn’t
used 100 % of time.
•
Dedicated Devices
Shared Devices
•
Assigned to several processes.
–
E.g., disk pack (or other direct access storage device)
can be shared by several processes at same time by interleaving their requests.
–
Interleaving must be carefully controlled by Device
Manager.
•
All conflicts must be resolved based on predetermined
policies to decide which request will be handled first.
Virtual Devices:
•
Combination of dedicated devices that have been
transformed into shared devices.
–
E.g, printers are converted into sharable devices
through a spooling program that reroutes all print requests to a disk.
–
Output sent to printer for printing only when all of a
job’s output is complete and printer is ready to print out entire document.
–
Because disks are sharable devices, this technique can
convert one printer into several “virtual” printers, thus improving both its
performance and use.
Buffering:· It is a process of storing data in memory area called Buffers while data is being transferred between two devices or between a device and an application. Buffering is done for 3 reasons:
a. To cope with the speed mismatch between producer (or sender) and consumer (or receiver) of a data stream.
b. To adapt · between the devices having different data-transfer size.
c. To support copy semantics for application I/O.
Disk Scheduling
TYPES OF DISK SCHEDULING ALGORITHMSFirst Come-First Serve (FCFS)
Shortest Seek Time First (SSTF)
Elevator (SCAN)
Circular SCAN (C-SCAN)
LOOK
Given the following queue -- 95, 180, 34, 119, 11, 123, 62, 64 with the Read-write head initially at the track 50 and the tail track being at 199 let us now discuss the different algorithms.
1. First Come -First Serve (FCFS)

2. Shortest Seek Time First (SSTF):- In this
case request is serviced according to next shortest distance. Starting at 50, the
next shortest distance would be 62 instead of 34 since it is only 12 tracks
away from 62 and 16 tracks away from 34. The process would continue until all
the process are taken care of. For example the next case would be to move from
62 to 64 instead of 34 since there are only 2 tracks between them and not 18 if
it were to go the other way. Although this seems to be a better service being
that it moved a total of 236 tracks, this is not an optimal one. There is a
great chance that starvation would take place. The reason for this is if there
were a lot of requests close to eachother the other requests will never be
handled since the distance will always be greater.
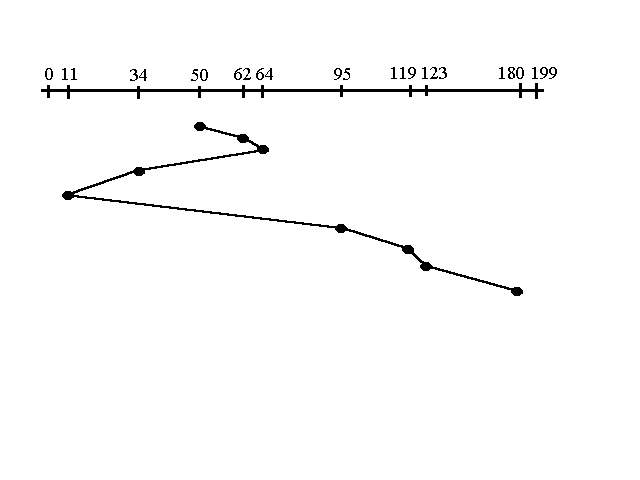
3. Elevator
(SCAN): This approach works like an elevator does. It scans down towards the nearest
end and then when it hits the bottom it scans up servicing the requests that it
didn't get going down. If a request comes in after it has been scanned it will
not be serviced until the process comes back down or moves back up. This
process moved a total of 230 tracks. Once again this is more optimal than the
previous algorithm, but it is not the best.
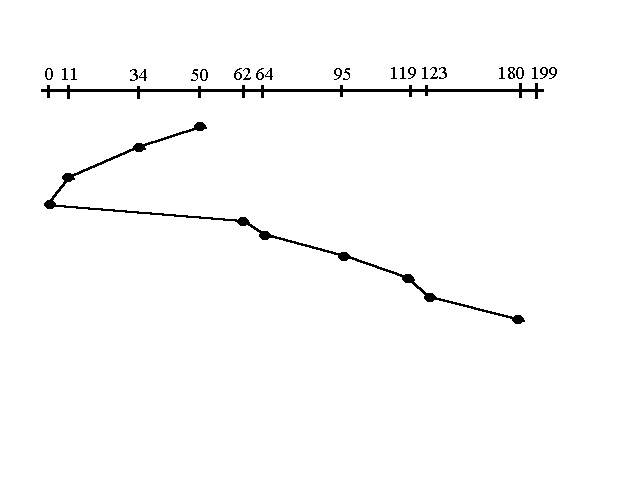
4. Circular
Scan (C-SCAN) :
Circular scanning works just like the elevator to some extent. It begins its scan toward the nearest end and works it way all the way to the end of the system. Once it hits the bottom or top it jumps to the other end and moves in the same direction. Keep in mind that the huge jump doesn't count as a head movement. The total head movement for this algorithm is only 187 track, but still this isn't the mose sufficient.
Circular scanning works just like the elevator to some extent. It begins its scan toward the nearest end and works it way all the way to the end of the system. Once it hits the bottom or top it jumps to the other end and moves in the same direction. Keep in mind that the huge jump doesn't count as a head movement. The total head movement for this algorithm is only 187 track, but still this isn't the mose sufficient.

5. C-LOOK:
This is just an enhanced version of C-SCAN. In this the scanning doesn't go past the last request in the direction that it is moving. It too jumps to the other end but not all the way to the end. Just to the furthest request. C-SCAN had a total movement of 187 but this scan (C-LOOK) reduced it down to 157 tracks.
This is just an enhanced version of C-SCAN. In this the scanning doesn't go past the last request in the direction that it is moving. It too jumps to the other end but not all the way to the end. Just to the furthest request. C-SCAN had a total movement of 187 but this scan (C-LOOK) reduced it down to 157 tracks.

Disk Management:
*Disk
Formatting:
Low-level
formatting,
or physical formatting — Dividing a disk into sectors that the disk
controller can read and write.
*To use a disk to hold files, the operating system still needs to
record its own data structures on the disk
Partition the disk into one or more groups of cylinders
Logical formatting or “making a file system”
*Boot Block: A boot sector or boot block
is a region of a hard disk, floppy disk,
optical
disc, or other data storage device that contains machine
code to be loaded into random-access memory (RAM) by a computer
system's built-in firmware. The purpose of a boot sector is to allow the boot process of a
computer to load a program (usually, but not necessarily, an operating
system) stored on the same storage device. The location and size of the
boot sector (perhaps corresponding to a logical disk sector)
is specified by the design of the computing platform.
*Bad Block: A bad sector is a sector
on a computer's disk drive or flash
memory that cannot be used due to permanent damage (or an OS inability to
successfully access it), such as physical damage to the disk surface (or
sometimes sectors being stuck in a magnetic or digital state that cannot be
reversed) or failed flash memory transistors. It is usually detected by a disk
utility software such as CHKDSK or SCANDISK on Microsoft systems, or badblocks on
Unix-like systems. When found, these programs may mark the sectors unusable
(all file systems contain provisions for bad-sector marks) and the operating
system skips them in the future.
Swap-space Management:
Swap-space management: Swap-space management is low- level task of the operating
system. The main goal for the design and implementation of swap space is to
provide the best throughput for the virtual memory system.
Swap-space use: The operating system needs to release sufficient main
memoiy to bring in a process that is ready to execute. Operating system uses
this swap space in various way. Paging systems may simply store pages that have
been pushed out of main memoiy. Unix operating system allows the use of
multiple swap spaces. These swap space are usually put on separate disks, so
the load placed on the I/O system by paging and swapping can be spread over the
systems I/O devices. Swap-space location: Swap space can reside in two places:
- Separate disk partition
- Normal file system
Disk Reliability:
•
Several
improvements involve the use of multiple disks working cooperatively.
•
Disk striping: group of disks used as one unit.
•
RAID (Redundant Array of Independent Disks)
improve performance and improve the reliability of the storage system by
storing redundant data.
–
Mirroring or shadowing keeps duplicate of
each disk.
Block interleaved parity uses much less
redundancy.
Thank you so much for sharing about software resource allocation
ReplyDelete