Unit-4
Multidimensional
Analysis and Descriptive Mining of Complex Data Objects
What are complex
data object?
1.
Many
advanced, data-intensive applications, such as scientific research and
engineering design, need to store, access, and analyze complex but relatively
structured data objects.
2.
These
objects cannot be represented as simple and uniformly structured records (i.e.,
tuples) in data relations.
3.
These
kinds of systems deal with the efficient storage and access of vast amounts of
disk-based complex structured data objects.
4.
These
systems organize a large set of complex data objects into classes, which
are in turn organized into class/subclass hierarchies.
5.
Each
object in a class is associated with (1) an object-identifier, (2) a set
of attributes that may contain sophisticated data structures, set- or
list-valued data, class composition hierarchies, multimedia data, and (3) a set
of methods that specify the computational routines or rules associated with
the object class.
How can we
Generalize the Structured Data
Typically, set-valued data can be generalized by:-
(1) Generalization
of each value in the set to its corresponding higher-level concept,
(2) Derivation
of the general behavior of the set, such as the number of elements in the
set, the types or value ranges in the set, the weighted average for numerical
data, or the major clusters formed by the set.
Suppose that the hobby of
a person is a set-valued attribute containing the set of values {tennis,
hockey, soccer, violin, this set can be generalized to a set of high-level
concepts, such as {sports, music, computer games}
How Aggregation
and Approximation is done in Spatial and Multimedia Data Generalization
1.
Aggregation and approximation are
another important means of generalization
2.
In
a spatial merge, it is necessary to not only merge the regions of similar types
within the same general class but also to compute the total areas, average
density, or other aggregate functions while ignoring some scattered regions
with different types if they are unimportant to the study.
3.
Spatial
aggregation and approximation. Suppose that we have different pieces of land
for various purposes of agricultural usage, such as the planting of vegetables,
grains, and fruits. These pieces can be merged or aggregated into one
large piece of agricultural land by a spatial merge. However, such a piece of
agricultural land may contain highways, houses, and small stores. If the
majority of the land is used for agriculture, the scattered regions for other
purposes can be ignored, and the whole region can be claimed as an agricultural
area by approximation
4.
A
multimedia database may contain complex texts, graphics, images, video
fragments, maps, voice, music, and other forms of audio/video information
5.
Generalization
on multimedia data can be performed by recognition and extraction of the
essential features and/or general patterns of such data. There are many ways to
extract such information. For an image, the size, color, shape, texture,
orientation, and relative positions and structures of the contained objects or
regions in the image can be extracted by aggregation and/or approximation. For
a segment of music, its melody can be summarized based on the
approximate patterns that repeatedly occur in the segment, while its style can
be summarized based on its tone, tempo, or the major musical instruments
played.
What
is Spatial Data Mining?
1.
A
spatial database stores a large amount of space-related data, such as maps,
preprocessed remote sensing or medical imaging data, and VLSI chip layout data.
Spatial databases have many features distinguishing them from relational
databases.
2.
Spatial
data mining refers to the extraction of knowledge, spatial relationships, or
other interesting patterns not explicitly stored in spatial databases. Such
mining demands an integration of data mining with spatial database
technologies.
3.
It
can be used for understanding spatial data, discovering spatial relationships
and relationships between spatial and nonspatial data, constructing spatial
knowledge bases, reorganizing spatial databases, and optimizing spatial
queries.
4.
It
is expected to have wide applications in geographic information systems,
geomarketing, remote sensing, image database exploration, medical imaging,
navigation, traffic control, environmental studies, and many other areas where
spatial data are used.
5.
A
crucial challenge to spatial data mining is the exploration of efficient spatial
data mining techniques due to the huge amount of spatial data and the complexity
of spatial data types and spatial access methods.
“Can we
construct a spatial data warehouse?” Yes, as with relational data, we can
integrate spatial data to construct a data warehouse that facilitates spatial
data mining. A spatial data warehouse is a subject-oriented, integrated,
time-variant, and nonvolatile collection of both spatial and
nonspatial data in support of spatial data mining and spatial-datarelated decision-making
processes.
There are three
types of dimensions in a spatial data cube
1.
A
nonspatial dimension contains only nonspatial data. (such as “hot” for temperature
and “wet” for precipitation)
2.
A
spatial-to-nonspatial dimension is a dimension whose primitive-level data are
spatial but whose generalization, starting at a certain high level, becomes
nonspatial.eg:-city
3.
A
spatial-to-spatial dimension is a dimension whose primitive level and all of
its highlevel generalized data are
spatial.eg:equitemp.
Two types of measures
in a spatial data cube:
1.
A
numerical measure contains only numerical data. For example, one measure in a
spatial
data warehouse could be the monthly revenue of a region
2.
A spatial measure contains a collection of pointers
to spatial objects.eg temperature and precipitation
There
are several challenging issues regarding the construction and utilization of
spatial datawarehouses.
1.
The
first challenge is the integration of spatial data from heterogeneous sources
and systems.
2.
The
second challenge is the realization of fast and flexible on-line analytical
processing in spatial data warehouses.
Mining
Spatial Association
A spatial association rule is of
the form A=>B [s%;c%], where A and B are
sets of spatial or nonspatial predicates, s% is the support of the rule,
and c%is the confidence of the rule. For example, the following
is a spatial association rule: is
a(X; “school”)^close to(X; “sports center”))=>close
to(X; “park”) [0:5%;80%].
This rule states that 80% of
schools that are close to sports centers are also close to parks, and 0.5% of
the data belongs to such a case.
------------------------------------------------------------------------------------------------à
What is Multimedia
Data Mining?
A multimedia
database system stores and manages a large collection of multimedia data,
such as audio, video, image, graphics, speech, text, document, and hypertext
data, which contain text, text markups, and linkages.
Similarity Search in Multimedia Data
For similarity
searching in multimedia data, we consider two main families of multimedia
indexing and retrieval systems:
(1) description-based retrieval systems,
which build indices and perform object retrieval based on image descriptions,
such as keywords, captions, size, and time of creation;
(2) content-based retrieval systems,
which support retrieval based on the image content, such as color histogram,
texture, pattern, image topology, and the shape of objects and their layouts
and locations within the image.
In a content-based image retrieval
system, there are often two kinds of queries:
Image sample- based
queries and
image feature specification queries.
·
Image-sample-based
queries find all of the images that are similar to the given image
sample. This search compares the feature vector (or signature) extracted from
the sample with the feature vectors of images that have already been extracted
and indexed in the image database. Based on this comparison, images that are
close to the sample image are returned.
·
Image
feature specification queries specify or sketch image features like color,
texture, or shape, which are translated into a feature vector to be matched
with the feature vectors of the images in the database
Mining
Associations in Multimedia Data
1.
Associations
between image content and non image content features:
A rule like “If at least 50%
of the upper part of the picture is blue, then it is likely to represent sky” belongs to this
category since it links the image content to the keyword sky.
2.
Associations
among image contents that are not related to spatial relationships: A rule like
“If a picture contains two blue squares, then it is likely to contain one
red circle a swell” belongs to this category since the associations are all
regarding image contents.
3.
Associations among image contents related to spatial
relationships: A rule like “If a red triangle is between two yellow squares,
then it is likely a big oval-shaped object is underneath” belongs to this
category since it associates objects in the image with spatial relationship.
Several approaches have been
proposed and studied for similarity-based retrieval in image databases, based
on image signature
1.
Color
histogram–based signature: In this approach, the signature of an image includes
color histograms based on the color composition of an image regardless of its
scale or orientation. This method does not contain any information about shape,
image topology, or texture.
2.
Multifeature
composed signature: In this approach, the signature of an image includes a
composition of multiple features: color histogram, shape, image topology, and
texture.
“Can we
construct a data cube for multimedia data analysis?” To facilitate
the multidimensional analysis of large multimedia databases, multimedia data
cubes can be designed and constructed in a manner similar to that for
traditional data cubes from relational data. A multimedia data cube can contain
additional dimensions and measures for multimedia information, such as color,
texture, and shape.
What is Text
Mining?
Text databases (or document
databases), which consist of large collections of documents from various
sources, such as news articles, research papers, books, digital libraries,
e-mail messages, and Web pages. Text databases are rapidly growing due to the
increasing amount of information available in electronic form, such as
electronic publications, various kinds of electronic documents, e-mail, and the
World Wide Web .
What
is IR(Information Retrieval System)?
A typical
information retrieval problem is to locate relevant documents in a document collection
based on a user’s query, which is often some keywords describing an information
need, although it could also be an example relevant document. In such a search
problem, a user takes the initiative to “pull” the relevant information out
from the collection; this is most appropriate when a user has some ad hoc
(i.e., short-term)information need, such as finding information to buy a used
car. When a user has a long-term information need (e.g., a researcher’s
interests), a retrieval system may also take the initiative to “push” any newly
arrived information item to a user if the item is judged as being relevant to
the user’s information need. Such an information access
process is
called information filtering, and the corresponding systems are often
called filtering
systems or recommender
systems.
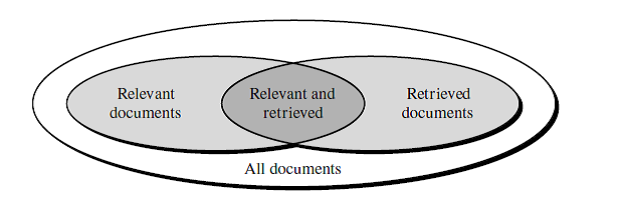
Basic Measures
for Text Retrieval: Precision and Recall
“Suppose that a
text retrieval system has just retrieved a number of documents for me based
on my input in
the form of a query. How can we assess how accurate or correct the system
was?”
Precision: This is the
percentage of retrieved documents that are in fact relevant to
the query (i.e., “correct”
responses). It is formally defined as
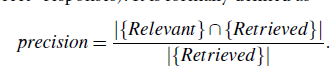
Recall: This is the
percentage of documents that are relevant to the query and were,
in fact, retrieved. It
is formally defined as
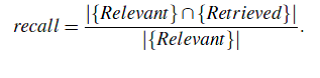
How Mining theWorld WideWeb is done?
The World Wide web serves as a
huge,widely distributed, global information service center
for news, advertisements,
consumer information, financial management, education,
government, e-commerce, and many
other information services. The Web also contains
a rich and dynamic collection of
hyperlink information and Web page access and usage
information, providing rich sources for data mining.
challenges
for effective resource and knowledge discovery in web
1.
The Web seems to be too huge for effective data
warehousing and data mining. The size of the Web is in the order of hundreds of
terabytes and is still growing rapidly. Many organizations and societies place
most of their public-accessible information on the Web. It is barely possible
to set up a data warehouse to replicate, store, or integrate all of the data on
the Web.
2. The complexity of Web pages is far greater than that of any traditional
text document
collection. Web pages lack a unifying structure.
3.
The Web is a highly dynamic information source. Not only does
the Web grow rapidly,
but
its information is also constantly updated.
4.
TheWeb serves a broad diversity of user
communities. The
Internet currently connects
more
than 100 million workstations, and its user community is still rapidly
expanding.
These challenges have promoted
research into efficient and effective discovery and use of resources on the
Internet.
Mining the WWW
1. Mining
theWeb Page Layout Structure
The basic
structure of a Web page is its DOM(Document Object Model) structure. The DOM
structure of a Web page is a tree structure, where every HTML tag in the page
corresponds to a node in the DOM tree. The Web page can be segmented by some
predefined structural tags. Thus the DOM structure can be used to facilitate
information extraction.
Here, we
introduce an algorithm called VIsion-based Page Segmentation (VIPS).
VIPS aims to extract
the semantic structure of a Web page based on its visual presentation
2.
Mining the Web’s Link Structures to Identify
Authoritative Web Pages
The Web consists not only of
pages, but also of hyperlinks pointing from one page to another.
These hyperlinks contain an
enormous amount of latent human annotation that can help automatically infer
the notion of authority. These properties of Web link structures have led
researchers to consider another important category of Web pages called a hub.
A hub is one or a set ofWeb pages that provides collections of links to
authorities.
What are the
various Data Mining Applications?
·
Data Mining for
Financial Data Analysis-
Design and
construction of data warehouses for multidimensional data analysis and
data mining: Financial data
collected in the banking and financial industry are often relatively complete,
reliable, and of high quality, which facilitates systematic data analysis and
data mining. One may like to view the debt and revenue changes by month, by
region, by sector, and by other factors, along with maximum, minimum, total,
average, trend, and other statistical information.
Loan payment
prediction and customer credit policy analysis: Loan payment
prediction and customer credit analysis are critical to the business of a bank.
Many factors can strongly or weakly influence loan payment performance and
customer credit rating.
Classification and clustering of customers for
targeted marketing: Classification and clustering methods can be used for customer
group identification and targeted marketing.
For example, we
can use classification to identify the most crucial factors that may influence
a customer’s decision regarding banking. Customers with similar behaviors
regarding loan payments may be identified by multidimensional clustering
techniques.
Detection
of money laundering and other financial crimes: To detect
money laundering
and other financial crimes, it is
important to integrate information from multiple
databases (like bank transaction
databases, and federal or state crime history databases), as long as they are
potentially related to the study
·
Data
Mining for the Retail Industry
Design and construction of data warehouses based on
the benefits of data mining: Because retail data cover a wide
spectrum (including sales, customers, employees, goods transportation,
consumption, and services), there can be many ways to design a data warehouse
for this industry.
Multidimensional
analysis of sales, customers, products, time, and region:
The retail industry requires timely information regarding
customer needs, product sales, trends,and fashions, as well as the quality,
cost, profit, and service of commodities
Analysis of the effectiveness of sales campaigns: The retail
industry conducts sales
campaigns using
advertisements, coupons, and various kinds of discounts and bonuses
to
promote products and attract customers
Customer retention—analysis of customer loyalty: With customer loyalty card
information,
one can register
sequences of purchases of particular customers. Customer loyalty and purchase
trends can be analyzed systematically
Product recommendation and cross-referencing of
items:
By mining associations
from sales
records, one may discover that a customer who buys a digital camera is
likely to buy
another set of items. Such information can be used to form product
recommendations.
Collaborative recommender systems use data mining techniques
to make
personalized product recommendations during live customer transactions,
based on the opinions
of other customers
·
Data
Mining for the Telecommunication Industry
Fraudulent
pattern analysis and the identification of unusual patterns:
Fraudulent activity
costs the telecommunication industry millions of dollars per year. It
is important to
(1) identify potentially fraudulent users and their atypical usage patterns;
(2) detect
attempts to gain fraudulent entry to customer accounts; and(3) discover unusual
patterns that may need special attention, such as busy-hour frustrated call
attempts, switch and route congestion patterns, and periodic calls from
automatic dial-out equipment (like fax machines) that have been improperly programmed
Multidimensional
association and sequential pattern analysis: The discovery
of association
and sequential patterns in
multidimensional analysis can be used to promote telecommunication services.
For example, suppose you would like to find usage patterns for a set of
communication services by customer group, by month, and by time of day.
Mobile
telecommunication services: Mobile telecommunication, Web and
information
services, and mobile computing
are becoming increasingly integrated and
common in our work and life.
Explain
the Social Impacts of Data Mining?
·
Ubiquitous
data mining is the ever presence of data mining in many aspects of our daily
lives. It can influence how we shop, work, search for information, and use a
computer, as well as our leisure time, health, and well-being. In invisible
data mining, “smart” software, such as Web search engines, customer-adaptive
Web services (e.g., using recommender algorithms), e-mail managers, and so on,
incorporates data mining into its functional components, often unbeknownst to
the user.
·
From
grocery stores that print personalized coupons on customer receipts to on-line stores
that recommend additional items based on customer interests, data mining has innovatively
influenced what we buy, the way we shop, as well as our experience while shopping.
·
Data
mining has shaped the on-line shopping experience. Many shoppers routinely turn
to on-line stores to purchase books, music, movies, and toys
·
Many
companies increasingly use data mining for customer relationship management (CRM),
which helps provide more customized, personal service addressing individual customer’s
needs, in lieu of mass marketing
·
While
you are viewing the results of your Google query, various ads pop up relating
to your query. Google’s strategy
of tailoring advertising to match the user’s interests is
successful—it has increased the clicks for the
companies involved by four to five times.
·
Web-wide
tracking is a technology that tracks a user across each site she visits.
So,while
Surfing the Web, information about
every site you visit may be recorded,which can provide
marketers with information reflecting your
interests, lifestyle, and habits
·
Finally,
data mining can contribute toward our health and well-being. Several
pharmaceutical companies use data mining software to analyze data when
developing drugs and to find associations between patients, drugs, and
outcomes. It is also being used to detect beneficial side effects of drugs
What are the Major concern of Data
mining?
A major social
concern of data mining is the issue of privacy
and data security, particularly as the amount of data collected on
individuals continues to grow. Fair information practices were established for
privacy and data protection and cover aspects regarding the collection and use
of personal data. Data mining for counterterrorism can benefit homeland
security and save lives, yet raises additional concerns for privacy due to the
possible access of personal data. Efforts towards
ensuring privacy
and data security include the development of privacy-preserving data mining
(which deals with obtaining valid data mining results without learning the
underlying data values) and data security–enhancing techniques (such as encryption)
What
are the Recent trends in Data mining?
Trends in data
mining include further efforts toward the exploration of new application areas,
improved scalable and interactive methods (including constraint-based mining),
the integration of data mining with data warehousing and database systems, the
standardization of data mining languages, visualization methods, and new
methods for handling complex data types. Other trends include biological data
mining, mining software bugs, Web mining, distributed and real-time mining,
graph mining, social network analysis, multi relational and multi database data
mining, data privacy protection, and data security
……………………………………………………………………………….
good
ReplyDeletevery relevant
ReplyDeleteWell explained .Keep updating Cognos TM1 online training hyderabad
ReplyDeletethis is so helpful
ReplyDeleteThis information you provided in the blog that is really unique I love it!! Thanks for sharing such a great blog Keep posting. Data Mining
ReplyDeletePHP Services
Website Development Company in Chennai
Magento Service Providers
Web Data Extraction Services
Payment Gateway Providers in India
Online Appointment Scheduling Software
Data Extraction Services Company
Free Appointment Scheduling Software
The information which you have provided is very good. It is very useful who is looking for
ReplyDeleteBig data consulting services Singapore
Data Warehousing services Singapore
Data Warehousing services
Data migration services Singapore
Data migration services
Thedata migration assistantis a free tool designed to help you transfer your contacts, calendar, email, pictures, music and other files from your Windows PC to your new Android phone. The data migration assistant can also help you transfer contacts from one Android phone to another.
ReplyDelete